
I recently went to the AI Engineer World's Fair in San Francisco and took away a lot of lessons about how the industry is approaching vertical artificial intelligence, vertical AI agents, and the future of healthcare AI platforms.
Vertical AI vs Horizontal AI
Building vertical AI applications presents unique challenges. The playbook is still being actively discovered. We have our own experiences and perspectives at Anterior, but are always keen to learn how everybody else is approaching it. We were grateful to be invited to talk at the AI Engineer World’s Fair as we knew it would be a great opportunity to learn from others.
There were a lot of great talks about vertical AI applications. The ones that stood out to us were:
- Harvey AI talking about their RAG system for indexing 10s of millions of legal docs and surfacing to lawyers
- Stride talking about their SMS-based support system for people needing healthcare advice
- WhyHow AI talking about how they scrape the web and surface trends to litigation lawyers
We came away with a lot of new learnings and some reinforcement of the perspectives we’ve developed at Anterior.
Here are our top 3 takeaways:
Domain expert driven evals are one key component of a wider eval system
Calvin Qi, Tech Lead Manager from Harvey AI pointed out that "there's not a single silver bullet eval". You need a combination of different eval mechanisms which provide different levels of information. For specialized domains, domain expert reviews are a key component.
Calvin describes the three levels that Harvey use:
- Human Evals - expert-led reviews to evaluate different algorithms and models
- Semantic Evals - expert-labeled evaluation sets that capture nuanced desired behavior
- Programmatic Evals - automated evaluation pipelines for rapid iteration and monitoring

We follow a similar approach at Anterior. Domain expert reviews are the highest quality signal you can get on the performance of your AI so we've built internal tooling to supercharge this.
A key component of this is a custom dashboard which surfaces all the context required for reviewing AI outputs as cleanly as possible.
These reviews give us both performance metrics on live cases and ground truths grouped by "failure mode" to enable targeted AI iteration. We then — like Harvey AI — also supplement this with programmatic evals.
Domain experts should be kept "in the loop" at the appropriate points
AI systems don't achieve 100% accuracy. They will always be a degree of error. The way to handle this is bring domain experts into the loop. But too much domain expert in the loop and it defeats the point of the AI system. The key is to bring them in at the right time.
Dan Mason shared how they do this with Avila, a text message based system for helping people with their medical treatments at home. They use an online LLM-as-judge and a dynamic confidence score to decide whether an SMS can go out to a patient or needs a clinician review. They've built an interface which makes it easy for the clinician to come in, understand the context and make a call on sending the message (or some variant of it).
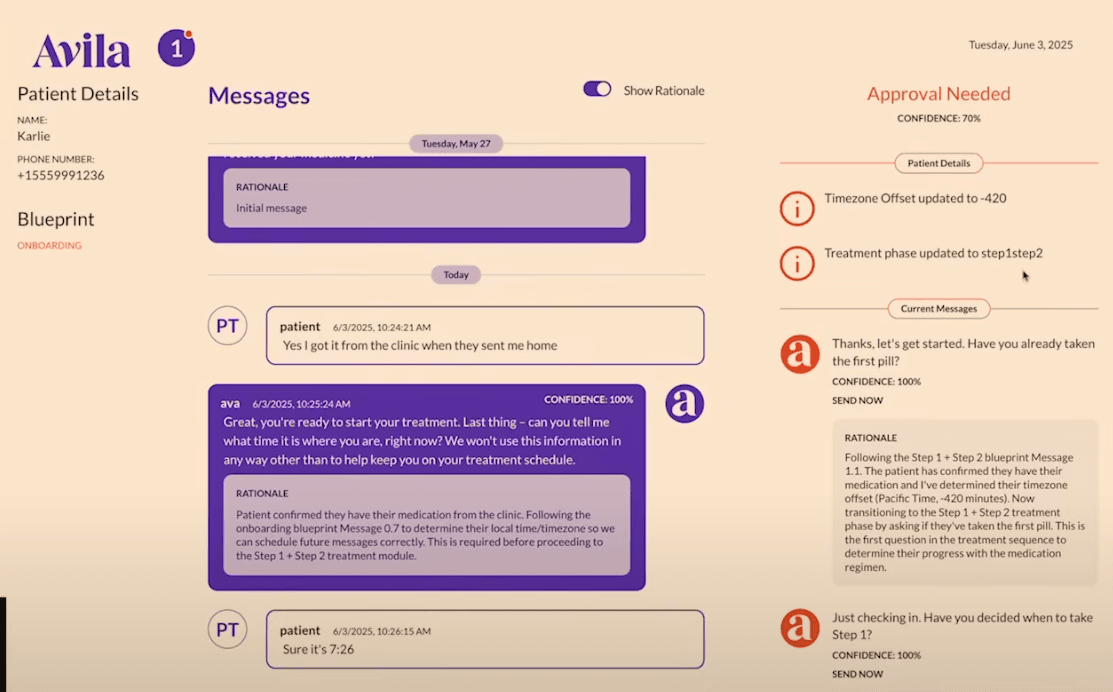
This is particularly important as we move towards a more agentic world. As agents grow in autonomy, it's critical that they know when to ask for help. Without checks and balances, errors can compound. As Tom Smoker pointed out: five agents with 95% accuracy executed in a sequence lead to 77% accuracy. In high-stakes domains like healthcare, this is unacceptable.
At Anterior, we believe healthcare administration workflows can be broken down into discrete tasks, with well defined inputs and outputs. Each task could be down either by a human or an AI. Humans should be brought into the loop for complex and nuanced tasks. The complexity that we entrust to AI will grow over time. So our role is to create these task definitions in code and continually identify where the handovers between AI and human should take place as the technology improves.
Structuring unstructured domain knowledge to anchor AI outputs
A helpful approach here is to make an explicit, structured representation of the domain knowledge. Tom Smoker from WhyHow.AI outlined how they do this in the legal domain using knowledge graphs. He outlined the advantages from doing so:
- you can visually inspect the graphs to understand the relations
- you can directly modify the graphs based on domain expertise
- you can empower domain experts to directly directly interact with the knowledge in natural language
He pointed out why this is critical in the legal domain, where things need to be precise, correct and grounded on the source information:
Lawyers don't like things being incorrect.. the whole industry is predicated on making things very specifically correct and proper and definitely in the right language - for building applications, probabilistic LLMs in isolation [without the proper grounding] don't work well for this.
Tom Smoker, WhyHow.AI
This high bar is true in healthcare too and we've taken similar approaches. We also encode domain knowledge in graphical representations and explicitly anchor all LLM outputs on the specific relevant inputs. We're excited to apply what we learned from Tom in this talk.
We believe expertise is important to building AI in healthcare
Overall, it was a great experience and we learned a lot. If you want to check out the original talks we referred to, check them out here:
- Scaling Enterprise-Grade RAG Systems: Lessons from the Legal Frontier - Harvey AI: https://www.youtube.com/live/a0TyTMDh1is?feature=shared&t=1480
- Case Study + Deep Dive - Telemedicine Support Agents with LangGraph+MCP: https://www.youtube.com/watch?v=sn79oS4MZFI
- Beyond Documents - Implementing Knowledge Graphs in Legal Agents - WhyHow.AI: https://www.youtube.com/live/RR5le0K4Wtw?feature=shared&t=11060
