Building a (clinical) brain is hard


Smart and clinical. Your doctor is both. Your AI should be too.
Maria's chemotherapy hung on one sentence that her insurer's AI couldn't understand.
46 pages. Nine days in queue. A "smart AI" system fluent in rules, but blind to what mattered: her estrogen-positive tumor was spreading. Her oncologist's handwritten justification was buried on page 32, invisible to an algorithm that didn’t think like a doctor.
The problem isn't computational. It's cognitive. Generic AI lacks what every clinician has: a medical brain. Building an AI replica of that brain is hard. But in healthcare, there’s no other option.
Spotlight — Building the complete AI solution for healthcare

We’ve written about how we’re building a healthcare-native infrastructure (the "nervous system") separately, but here, let’s focus on what’s at the core: an AI brain that thinks like a clinician.
Building a clinical brain… function by function
In biology, a brain senses, remembers, reasons, learns, and acts. At Anterior, this informs how we build: our teams of engineers and clinicians work together to translate the mechanics of clinical cognition into systems that can operate at scale in healthcare. The idea is simple: capture how clinicians think—and build it into code. We’re creating foundational clinical intelligence—more accurate than generic AI, and also generalizable across any clinical workflow. The rest of this piece walks through each of our clinical brain’s five functions, what it takes to build each right, and why you can’t fake it.

Sense… granularly
Sensing is a pre-requisite to reasoning. A single prior authorization packet can contain a skewed scan, an overlapping intake form, a handwritten medication list, and an EHR export from 2009. Generic AI treats this mess as noise. We don’t.
Our clinical AI can “see” as a clinician would. This is no simple task. OCR handles clean text well, but fails on noisy inputs. Vision models are resilient to mess, but prone to hallucination. So, we built a proprietary orchestration model on top of both: using OCR for structure and vision for resilience. Our brain can read through bad copies, ink streaks, folded corners, and physician handwriting that would stump most humans.
It also “understands” as a clinician would. Layout-aware processing preserves the visual structure that matters. This is important: lose layout, and you lose meaning—tables scramble, headers disappear, and checkboxes turn blank. Similarly, our granular temporal extraction translates cryptic medical shorthand (e.g., "PT × 6 wks", "injection 12/14/23") into normalized timelines that drive coverage decisions.
And every processed token carries byte-level sourcing, back to its original file and page, creating an immutable audit trail that lawyers and regulators can follow.
In Maria's case, this would mean her oncologist's handwritten note about estrogen-positive status wouldn’t get discarded as illegible noise. It’d be captured, tagged, validated, and mapped to the appropriate chemotherapy guidelines in real-time.
Remember… correctly
Clinical policy isn't static; it's versioned, fragmented, and constantly evolving. Coverage rules vary by payer, product line, region. That’s not a bug; it's a feature that reflects the complexity of medical care and the realities of business.
Generic AI tools crumble under this complexity. A model trained on January's coverage criteria will confidently apply outdated rules in March, with no way to detect the drift.
We’ve built a memory layer that mirrors how clinicians actually navigate policy. Our rules compiler ingests PDF guidelines and flowcharts, then generates machine-readable decision trees structured exactly how clinicians—and specifically, your clinicians—would walk through a coverage determination.
When policies change, each tree gets stored under version control like software code. Medical directors open "pull requests," clinical reviewers approve changes, and nothing goes live without proper oversight.
Our brain doesn't guess; it applies the right policy, the right way, every time. This means Maria’s chemotherapy authorization will always be evaluated against her insurer's current oncology guidelines, not the stale criteria that might have excluded newer targeted therapies.
Reason… expertly
Generic AI can sound smart. But it can’t prove it’s reasoning—or survive an audit. When coverage decisions affect patient care and face regulatory scrutiny, you need explainability, auditability, and repeatability.
Our reasoning function mirrors the accountability standards that govern real clinical practice. The engine walks each policy tree deterministically. It logs every decision point and the specific evidence that satisfied each requirement. When it approves a procedure, every "Yes" includes a precise pointer to the supporting documentation—not just "medical necessity was established," but "MRI ordered 6 weeks ago, documented on Page 17, Line 3 of the physician notes."
What if the system can't achieve near-certainty on a clinical determination? The case gets escalated to human review. No guesses. Even where it knows to deny, the system follows a crucial ethical boundary: it will approve care or escalate for further review, but never deny without some human supervision.
The complete reasoning chain lives in an immutable audit log that can be replayed in test environments, examined by compliance teams, and defended in regulatory proceedings. This isn’t just defensive. It can be operationally transformative: our chain-of-reasoning approach cut prior authorization review time by 72% per case when nurses used our Florence system in co-pilot mode, because transparent logic is faster to review and trust. Maria’s doctor should not have to wonder why a specific determination was made.
Learn… constantly
95% is not good enough in healthcare. A missed drug interaction, a misread contraindication, or a misapplied guideline can delay treatment, trigger unnecessary procedures, or worse. The real test of clinical AI isn't launch day performance, but whether it gets smarter every week after patients start depending on it.
At the deployment level, we built an adaptive learning engine. It continuously absorbs the specific nuances of each customer’s workflow—and updates its approach. This system improves with use, not just over time. It’s powered by a forward-deployed team of clinicians, supported by internal tools, who serve as a critical translation layer between new customer data and model understanding. The result: rapid, targeted performance gains grounded in real-world feedback.
At the system level, our failure mode ontology catalogs hundreds of specific error classes, and then tactically improves performance across each failure mode. This goes beyond classic error tracking; it's based off clinical taxonomy that mirrors how medical professionals categorize and learn from adverse events. We can do this because we’re built by clinicians.
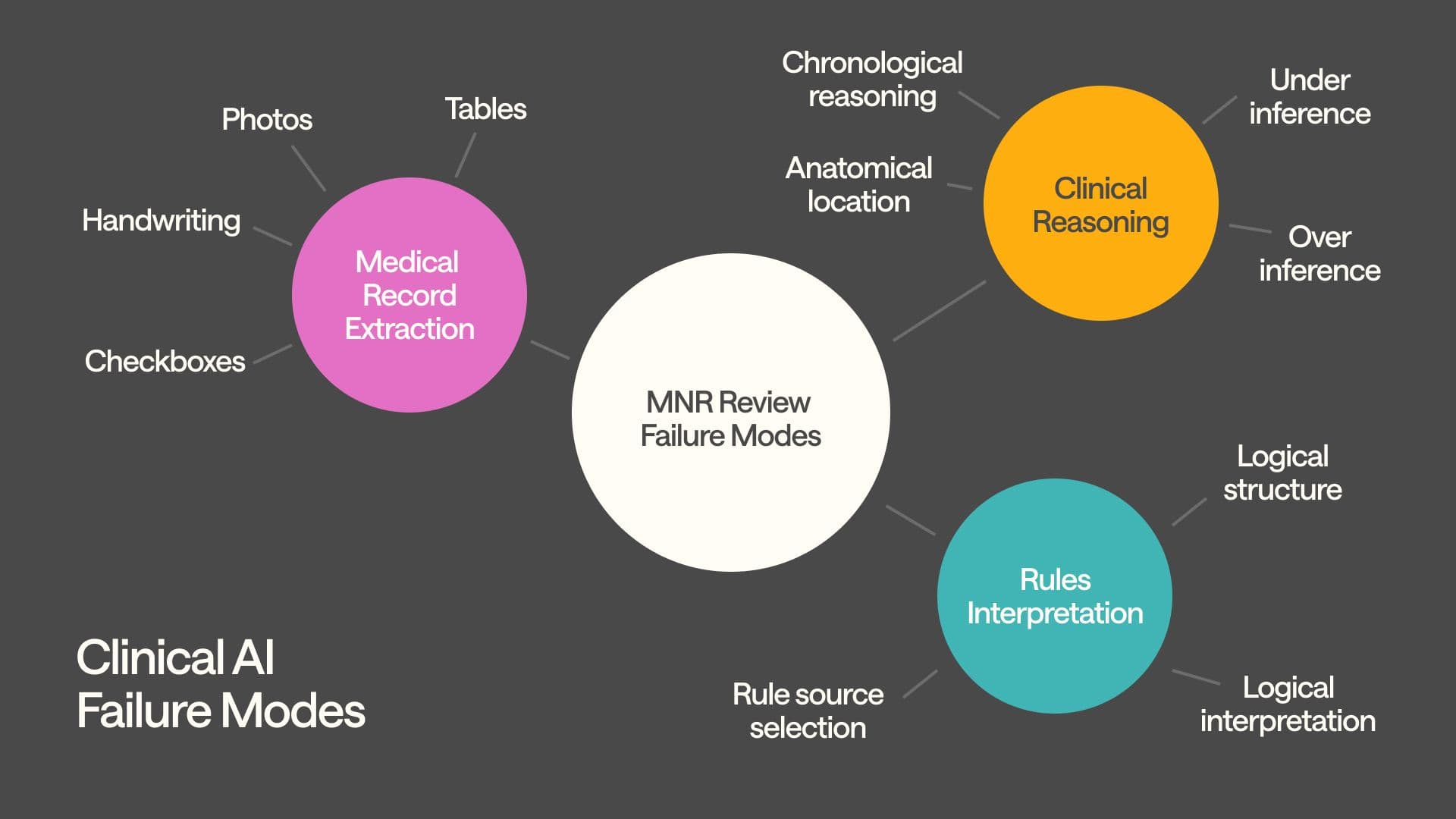
These in-house clinicians also manually audit both random and risk-weighted samples of system output, tagging issues in our internal tooling that get routed to the right engineering squad e.g., to the extraction engineering squad if they find data parsing errors, or the inference engineering squad for issues with guideline interpretation, and so on.
The results speak for themselves: our accuracy exceeded 99% when deployed for automated medical necessity reviews. This isn’t because we launched with perfect algorithms; but because our forward-deployed clinicians and engineers worked with the customer and built systems that learn from clinical feedback and improve continuously.
Generic AI vendors can't replicate this feedback loop, because they lack the clinical infrastructure to sustain it. They don't employ practicing clinicians, don't maintain failure taxonomies, and don't ship weekly improvements based on healthcare-specific insights. Without this loop, AI systems plateau; they work well enough for demos but fail to evolve with the clinical complexity they encounter in production. In Maria’s case, this means that if the system initially misses similar estrogen-receptor documentation patterns, our clinical team would flag it, categorize the failure mode, and ensure the fix was deployed system-wide within days
Act… quickly
If it can't act, it’s academic. Effective clinical AI closes the loop, turning determinations into outcomes that move patient care forward.
Our clinical brain doesn’t just decide—it executes. Every determination outputs structured data (in FHIR), generates supporting documentation (e.g. provider letters), and supports CMS DTR workflows—so approvals like Maria’s reach her oncologist’s EHR within hours, not days.
Don’t trust your AI transformation to generic AI
Generic AI skips the hard parts: clinical structure, clinical memory, clinical reasoning, clinical learning. That's fine for filing assistance. But it's not enough when patients are waiting.
Healthcare doesn’t need “smarter AI’. It needs medical intelligence. We’ve built it. Are you deploying it?